
When I started writing this newsletter nearly three years ago, I never imagined that the words I write on my keyboard would take such an important place in my life. All the interactions I have with you, whether online or offline, are always amazing and give me wings.
Today I want to introduce a new feature in the Data News galaxy.
I don't talk much about my freelance life in Data News because sometimes I think that's not the contract we have together. Data News promise is to give you, every week, the links I've hand-picked with my spicy opinion about them. Since the beginning of the year balance between content and freelancing has gone from 80/20—80% client stuff and 20% to content—to 30/70. This is mainly due to the fact that I've done my annual University lectures and talked at 7 events since the beginning of the year.
Let's be honest, I'm also a bit stupid. At every event I talk, I decide to do a new presentation. That's great because it helps me innovate and pushes me to new horizons every time, but it takes time to assimilate chunks of work in order to produce creative keynotes.
All of this is made possible thanks to my Data News curation. Thanks to the time I spend reading content, forging ideas and chatting with all of you, I get inspired and my crazy brain invents things. And I want you to have the same superpowers as me. This is what motivates me.
PS: Fast News ⚡️ at the very end if you want to keep this story. Which will makes me sad, but I understand.
There is a problem
Data News have grown so much since the beginning, I currently have 4500 members on blef.fr. I have sent 132 Data News editions which represents 2500 links (~20 links per edition).
But there's a big problem: all my old Data News is dead content.
I mean, there is a big difference between podcast for instance and news blogging like I'm doing. When you subscribe to a new podcast you often scroll over the past episodes of the creator. When someone subscribe to the Data News rarely the person goes over my old news.

All these 2500 links that I've liked and commentated. When I'm looking at all these links for the most of them they are timeless and I think they can still bring a lot of value to all of you.
That's why I want to re-activate my old content.
The Explorer
One year and half ago I had developed the Explorer. The Explorer is a search bar that let's you search over all the links that I have shared in the 132 Data News editions.
It was my first step in this journey to make my handpicked links browsable and usable to everyone. While I'm not good at marketing it there is a few number of you using it every month but I think it could be used way more.
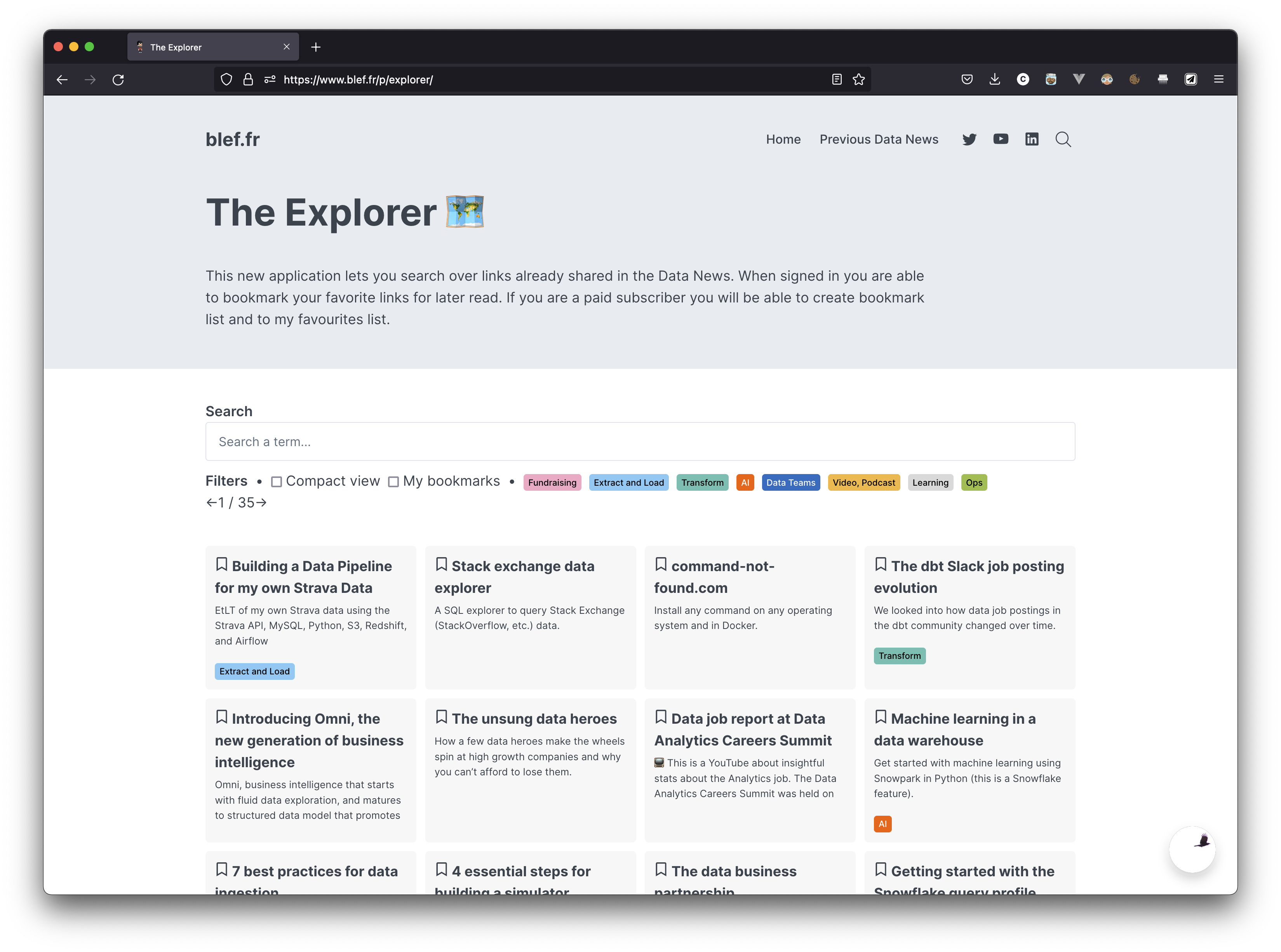
But I want to go further.
Introducing the Recommendation
2500 links is a huge amount and sometimes this is like finding a needle in a haystack. That's why I've developed a new feature: a recommendation module.
Data News recommendation will give you every week a single link that you should have clicked on.
For the moment the recommender will be based on your click history. In every Data News email I send you I know which link you clicked on, so I'm able to leverage this information to recommend you content.
This is just the beginning and for the moment the algorithm is very trivial, this is a collaborative filtering algorithm that recommends you links you did not clicked on that have been clicked by members with the same click behaviour as you.
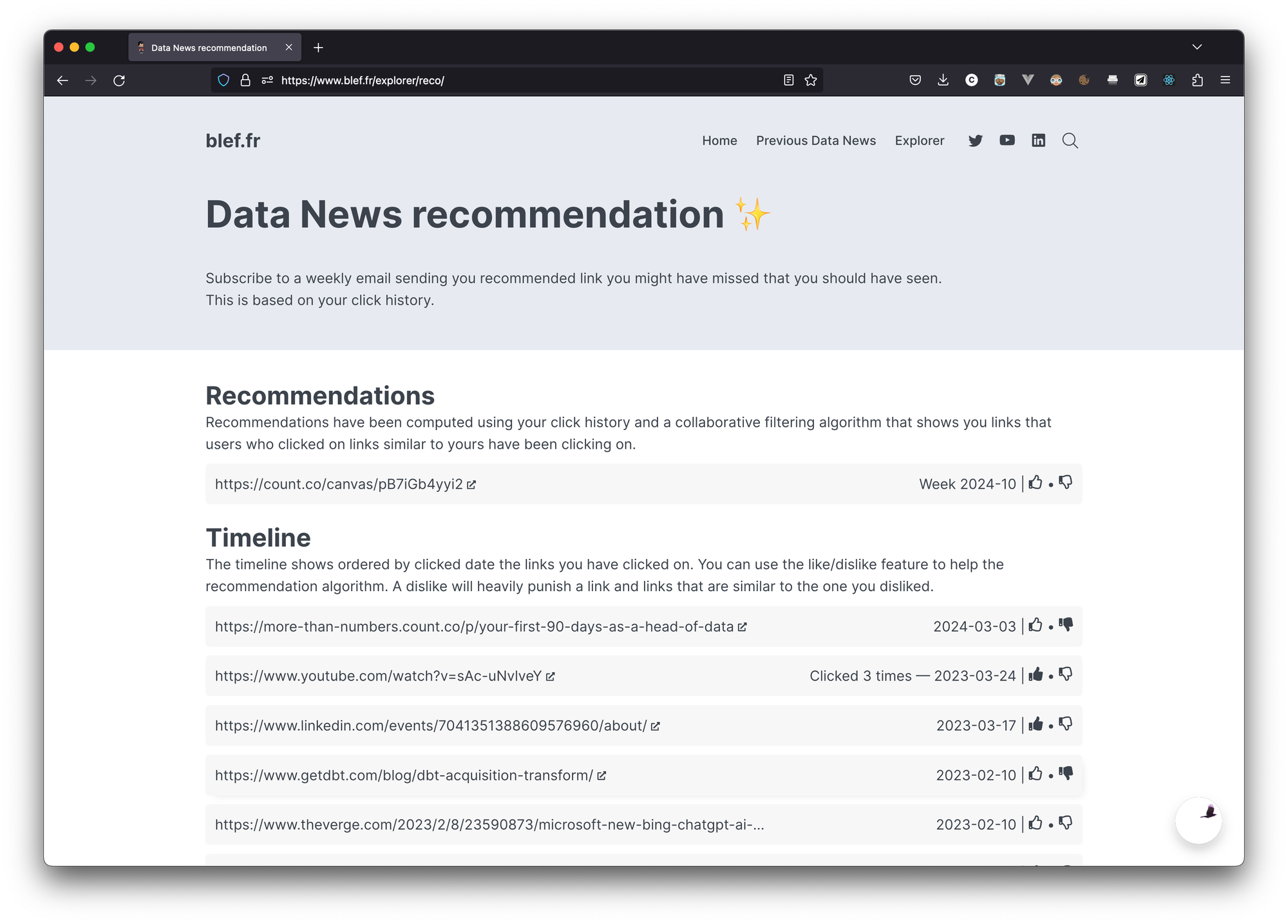
As you can see in the screenshot of the feature in the Recommendation panel you can see the link that have been recommended to you and the link you've clicked on. In order to for me to get your feedback you have the possibility to like / disliked all the links (wether it's recommendation or clicked links).
Christophe, why did you make this? No one asked for it.
Yes no one asked for it but let me extend deeper on the why
- Frustration — Like I said before, I'm super frustrated by all the content that I've referenced that is "dead". I'm pretty sure that if I successfully reactivate this content I can: generate more traffic on blef.fr, diversify my revenue and bring more knowledge to the data community.
- It's a showcase — It can be an educational project showing others how you can orchestrate and schedule a small-scale AI application.
- It's fun and rewarding — Looking from my side I like the fact that every week members will have a gift coming from me being this recommendation.
- Why not? — Finally I don't run any playbook, why not trying stuff?
Architecture
I said it, while being a new feature to the blog this is as well an educational projet I can use to showcase technologies. See below the global architecture I've used to make this links recommender work.
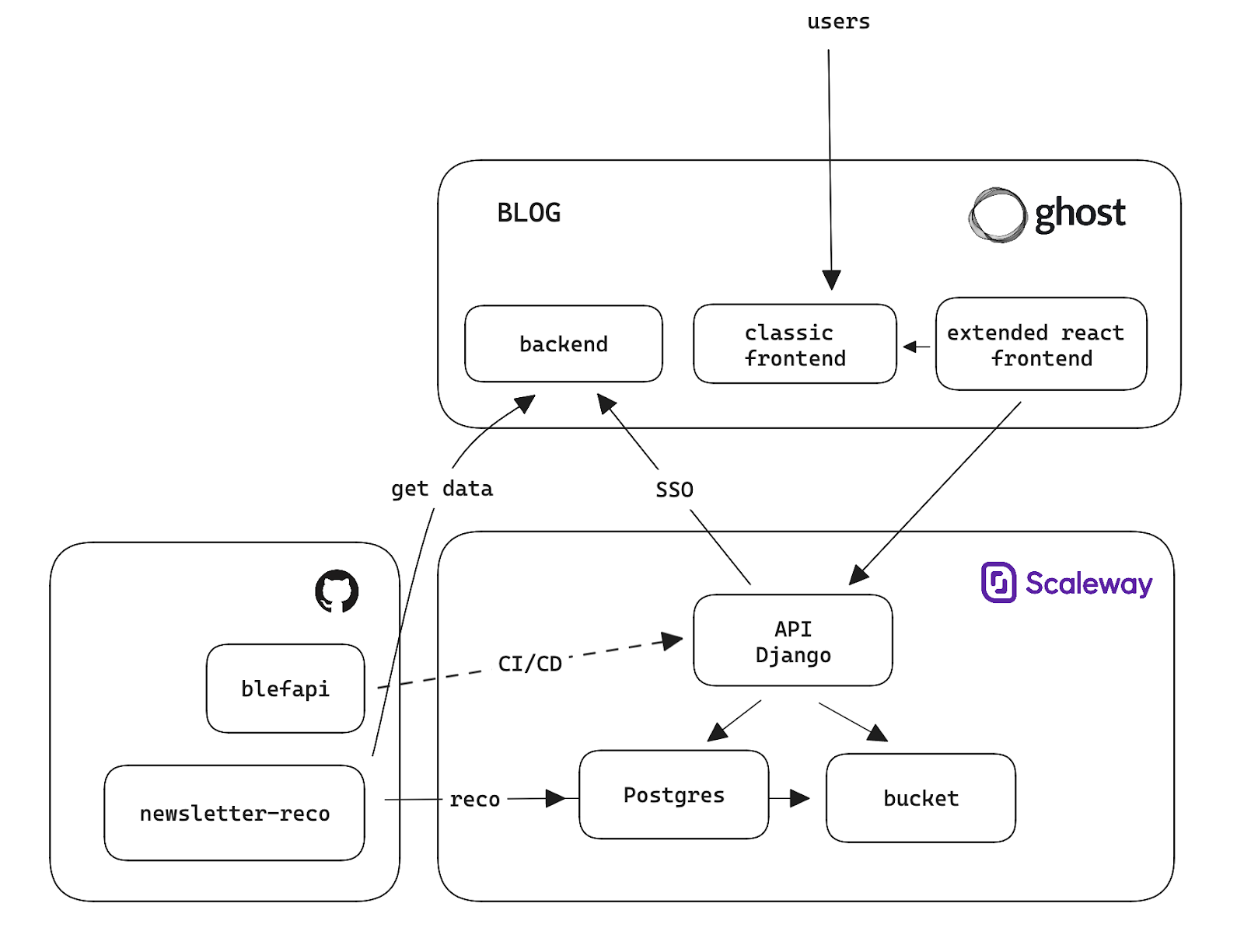
- Ghost — My blog is hosted on ghost.org, I really like Ghost because it's open-source (but I use the paid hosted version) and give me the possibility to extend the blog with custom code. The main part of the blog is just a bunch of Handlebars templates connected to Ghost Content API. I extended the website by embedding a React application that powers the custome frontend of the Explorer and Recommendation.
- blefapi — In order to make the React apps working I need to have a custom backend that I've developed with Django, this backend connects to Ghost using some kind of SSO (with JWT), which means that I don't need to create another login page, once you're a member you can use all my extended features. The Django app uses a Postgres as a database and a bucket to host a few static files. Everything is hosted on Scaleway (a French cloud company).
- CI/CD — Everything is just deployed from Github Actions, wether it's the React application of the Django API I just need to push and it will deploy a new version.
- newsletter-reco — This is where the recommendation magic happens. This is small pipeline that needs to get the activity data from the blog API, do a bit a feature engineering, recommend an article for every member and then publish the recommendations to the blefapi. Under the hood (see below) it uses dlt, DuckDB / pandas and Github Actions.
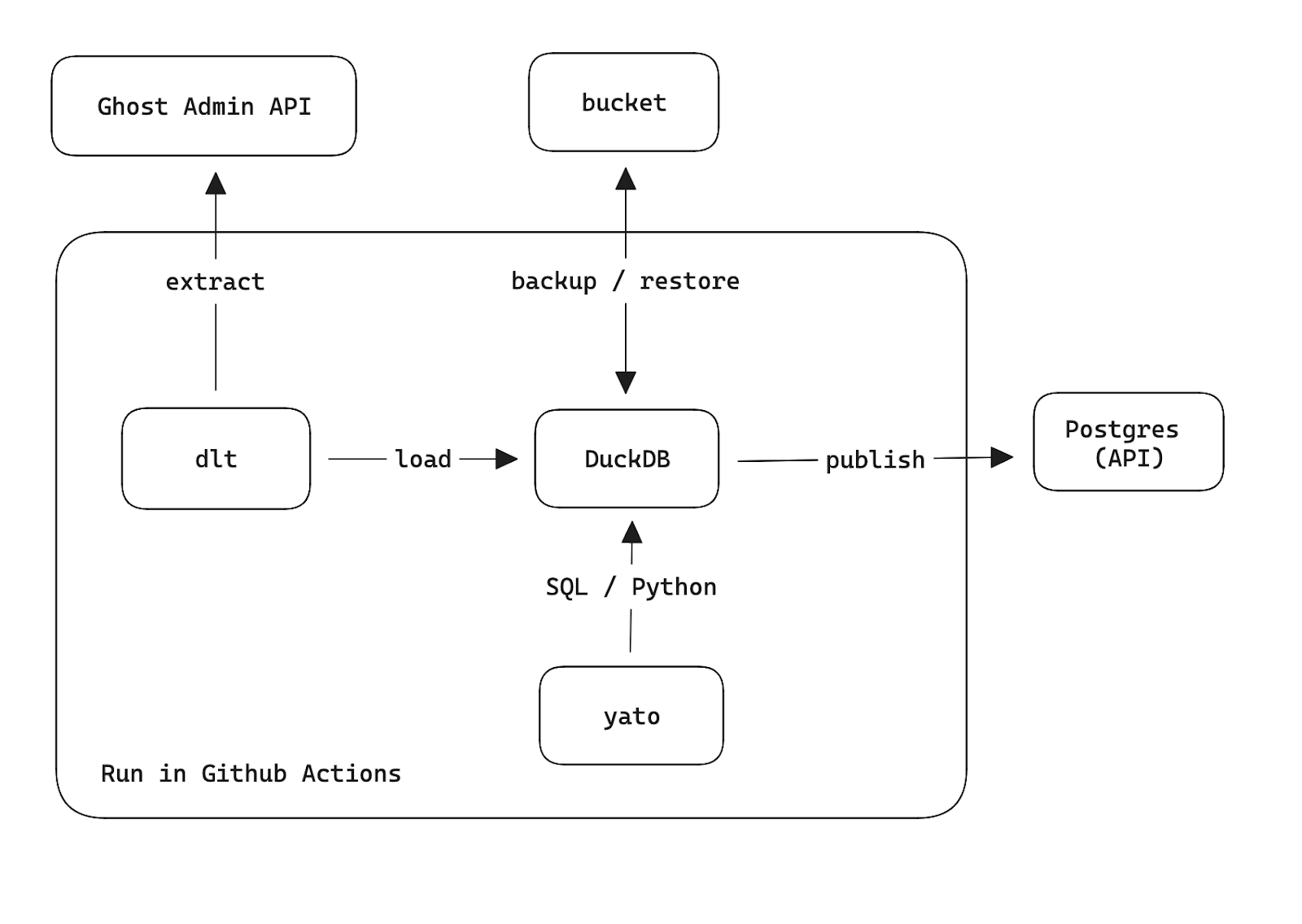
The recommendation is fairly simple, it uses dlt to do the extract-load from the Ghost API then dlt loads the data into a DuckDB database then this DuckDB data is transformed using SQL / Python transformations orchestrated by yato. In order to publish the recommendation to the API it uses the DuckDB ATTACH capabilities by directly inserting records to the Postgres database (it's a hack, but works). All of this will run into Github Actions every week to produce a new recommendation for everyone.
Next steps
I'll work incrementally in the next week on the recommendation, I'm open to all suggestion and I'd love to get your feedback on this, you can even do Pull Requests on the code if you feel it. Here what I plan to add in the following weeks:
- Subscribe to an additional email to receive the recommendation on Tuesday (if you really want to receive recommendation by email answer to this email I'll opt you in directly).
- Use GenAI to summarise all the links database to give you a summary of each link that have been recommended to you—saving you one-click maybe
- Improve the recommendation algorithm by using an item-based approach and embeddings
- Taking into account the like / dislike from the Timeline
- Develop public BI-as-code dashboard showing metrics about the content and showcasing Evidence and Observable
Bonus: yato
While working on the recommender I've developed something else called yato. yato stands for yet another transformation orchestrator and is the smallest DuckDB SQL orchestrator on Earth.
The idea behind yato is to provide a Python library (pip install yato-lib) that you can run either with Python code or via CLI that run all the transformations in a given folder against a DuckDB database.
yato uses SQLGlot to guess the underlying DAG and run the transformations in the right order. For the moment yato is tight to DuckDB, philosophically yato has been developed like black (the formatter) you just have one required parameter: a transformation folder and then you can do yato run .
I don't think yato will ever replace dbt Core, SQLMesh or lea, yato is just lighter alternative that you can use with your messy SQL folder.
It was a special announcement for me, I hope you'll understand and receive this news as excited as I'm.
And because I still want you to get a few news below a very fast news.
Very Fast News ⚡️
- Elon Musk decided to sue OpenAI for violating company principles by putting profits and commercial interest first. Funny to see this from Elon Musk the philanthropist.
- Google is slowly loosing the race for (Gen)AI, so people are starting to call for Sundar Pichai to step down.
- Anthropic released Claude 3 — that seems to achieve great results in benchmarks with "sophisticated vision capabilities".
- HuggingFace released Enterprise Hub — A private space to use HF features but in a dedicated space.
- Yann Lecun went on Lex Fridman podcast — He chatted for almost 3h. I did not listen the podcast yet but I guess he chatted about the concept of intelligence like he he used to do.
- Sicara released a tech radar about AI technologies. It includes 4 pillars: algorithm, data, methods and industrialisation. This is funny to see parquet as a technology still to adopt.
- Easy introduction to real-time RAG — Showcase how you can include your Langchain / OpenAI pipeline into a classic Kafka / Pinot infrastructure.
- ClickHouse acquired chDB a DuckDB alternative and achieved the 1 trillion challenge (with classic ClickHouse) in under 3 minutes for $0.56.
- Snowflake now support trailing commas and partners with Mistral AI to bring models to the warehouse, we also learn that Snowflake Ventures also invested in Mistral AI. Long gone are the days when mistral was French.
- Orchestra released a free-tier platform to rapidly build and monitor data products. Orchestra is graphical solution to define DAGs and orchestrates different parts of the Modern Data Stack.
- Use Ibis to load data from other databases to Snowflake. This is similar to the ATTACH I did in my recommender with DuckDB.
- How to measure a data platform — A great article discussion the metrics tree we need to put in place as a data team. I really like it.
See you next week ❤️ — and please give me feedback wether you like it or not.