Databricks, Snowflake and the future
Databricks and Snowflake summits featured major announcements, including open-sourcing their catalogs and enhancing Iceberg compatibility. This article covers all the key updates you need to know.

Every year, the competition between Snowflake and Databricks intensifies, using their annual conferences as a platform for demonstrating their power. This year, the Snowflake Summit was held in San Francisco from June 2 to 5, while the Databricks Data+AI Summit took place 5 days later, from June 10 to 13, also in San Francisco. The conferences were expecting 20,000 and 16,000 participants respectively.
Snowflake is listed and had annual revenue of $2.8 billion, while Databricks achieved $2.4 billion—Databricks figures are not public and are therefore projected. Snowflake was founded in 2012 around its data warehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014.
Snowflake and Databricks have the same goal, both are selling a cloud on top of classic1 cloud vendors. In the data world Snowflake and Databricks are our dedicated platforms, we consider them big, but when we take the whole tech ecosystem they are (so) small: AWS revenue is $80b, Azure is $62b and GCP is $37b.
The Google search results give an idea of the market both tools are trying to reach. Using a quick semantic analysis, "The" means both want to be THE platform you need when you're doing data. Both companies have added Data and AI to their slogan, Snowflake used to be The Data Cloud and now they're The AI Data Cloud.
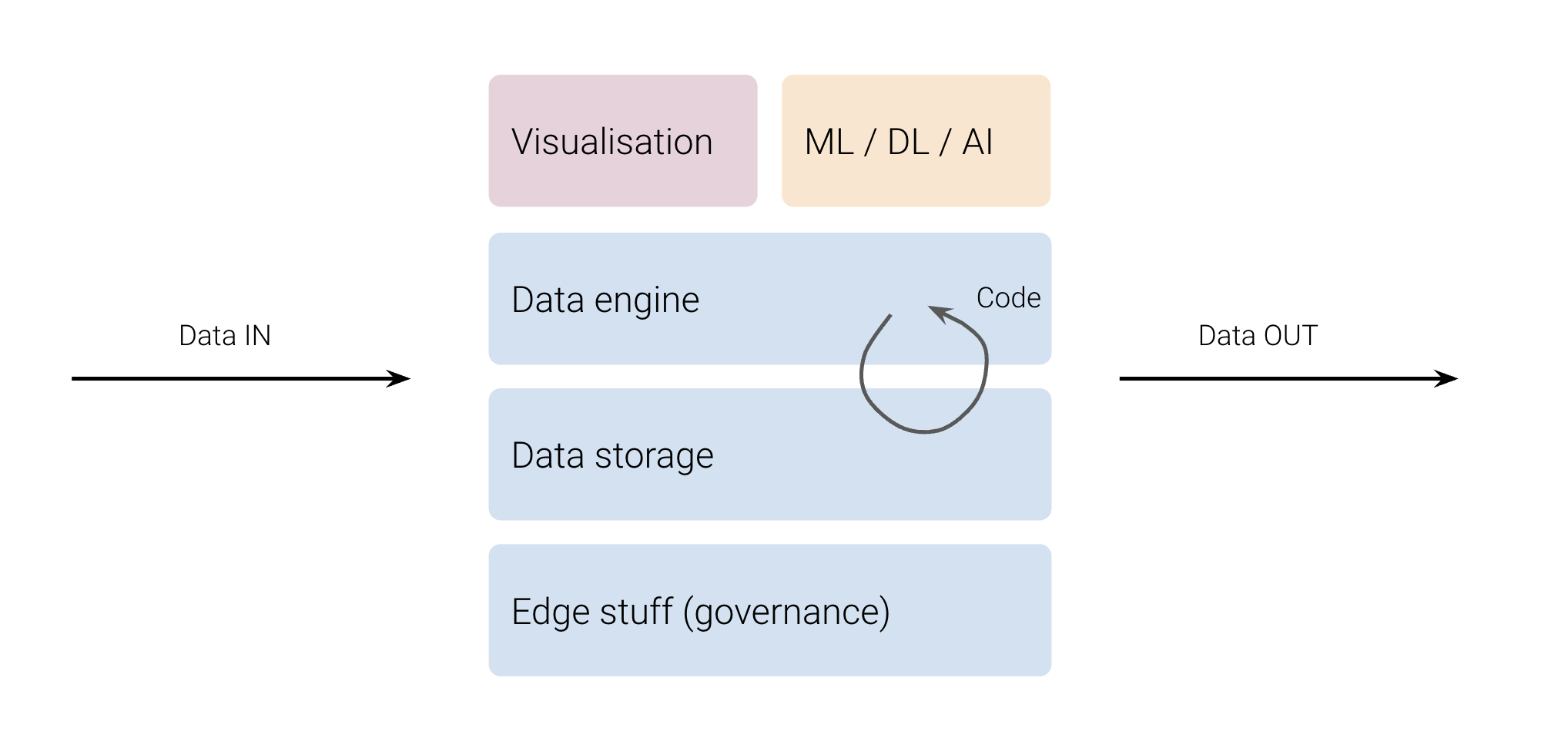
Below a diagram describing what I think schematises data platforms:
- Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata.
- Data engine — you need to make computations on data, the computation can be volatile or be materialised back to the storage
- Programmable — you need to run code on your platform, whatever the language or the technology at some point you need to translate your business logic into a programmatic logic
- Visualisation — you need to visualise the output of the computed data because charts are often better than table
- AI — you need to be proactive or predictive, that's when machine learning or deep learning enters, more generally today AI.
- In order to make all of this work data flows, going IN and OUT.
- Edge stuff — and then everything else that goes with it like privacy, observability, orchestration, scheduling, governance, etc. which might be required or not depending on the company maturity.
When we look at platforms history what characterises evolution is the separation (or not) between the engine and the storage. Good old data warehouses like Oracle were engine + storage, then Hadoop arrived and was almost the same you had an engine (MapReduce, Pig, Hive, Spark) and HDFS, everything in the same cluster, with data co-location. Then cloud changed everything and created a new way separating the storage from the engine leading to ephemeral Spark clusters with S3 and then, Cambrian explosion, engines and storage multiplied.
This is the fundamental difference between Snowflake and Databricks.
Snowflake sells a warehouse, but it's really more of a UX. A UX where you buy a single tool combining engine and storage, where all you have to do is flow data in, write SQL, and it's done. Databricks sells a toolbox, you don't buy any UX. Databricks is terribly designed, it's an amalgam of tools, they have a lot of products doing the same thing—e.g. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with Databricks you buy an engine.
At least, that's what the two platforms are all about. Ultimately, they both want to become everything between the left and the right arrows.
Now that I've introduced the two competitors, let's get down to business. In this article I'll cover what Snowflake and Databricks announced at their respective summits and why Apache Iceberg in the middle crystallised all the hype.
Snowflake Summit
Snowflake took the lead, setting the tone. I won't delve into every announcement here, but for more details, SELECT has written a blog covering the 28 announcements and takeaways from the Summit. If you're a Snowflake customer, I recommend reading Ian's insights. His business is centered on Snowflake, and he always offers the best perspectives.
Here what I think summarises well the summit:
- Apache Iceberg support — it means Snowflake engine is now able to read Iceberg files. In order to read Iceberg files you need a catalog, Snowflake support external catalogs—like AWS Glue—and they will open-source Polaris, in the next 90 days, their own Apache Iceberg catalog.
If you're not familiar with Iceberg, it's an open-source table format built on top of Parquet. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table. For a comprehensive introduction to Iceberg, I recommend reading my friend Julien's Iceberg guide. - Native CDC for Postgres and MySQL — Snowflake will be able to connect to Postgres and MySQL to natively move data from your databases to the warehouse. This could be a significant blow to Fivetran and Airbyte's business. While the exact pricing hasn't been revealed yet, the announcement emphasises cost-effectiveness.
- Store and run whatever you want on Snowflake — They bring a serverless / container philosophy to Snowflake as you will be able to store your AI models, run pandas code or any container.
- Dark mode interface — Ironically it was their closing announcement, their most asked feature and their Reddit most liked post following the announcement. I found it a bit ridiculous but it showcases how much Snowflake is a UX first platform.
From the start, Snowflake has been a straightforward platform: load data, write SQL, period. This approach has always appealed analysts, analytics engineers, and pragmatic data engineers. However, to capture a larger market and address AI use-cases, Snowflake needed to break through its glass ceiling. To me, that's what these major announcements are. Snowflake becomes Databricks.
Databricks Data+AI
I didn't attend either summit in person. While I enjoy these events, I prefer avoid flying for ecological reasons, and large gatherings can be challenging for an introvert like me. Watching the Data+AI Summit from home did give me a bit of FOMO, but the Snowflake Summit did not. Databricks successfully built hype during the event, announcements after announcements.
Once again it boils down to the nature of the platform, Snowflake is insanely boring, even if use-cases are different Snowflake solution standardise everything, when it comes to Databricks, creativity arise—or we can call it tech debt. By the multiplicity of products or ways to handle data shiny stuff can appeal everyone.
Here what Databricks brought this year:
- Spark 4.0 — (1) PySpark erases the differences with the Scala version, creating a first class experience for Python users. (2) Spark versions will become even easier to manage with Spark Connect, allowing other languages to run Spark code—because Spark Connect decouple the client and the server. (3) Spark 4.0 will support ANSI SQL and many other things.
- Databricks AI/BI — Databricks has introduced AI/BI, a smart business intelligence tool that blends AI-powered low-code dashboarding solution with Genie, a conversational interface. AI/BI will be able to semantically understand and use all the objects you have in your Databricks instance. Visually the dashboarding solution looks like a mix between Tableau and Preset.
- Serverless compute — This is something that keeps bridging the gap in term of user experience, because manage Spark cluster is painful, Spark serverless let's you run a Spark job without worrying about the execution. Still, serverless compute does not support SQL.
- Buying Tabular — Before the last bullet point, it was already something big. Databricks bought Tabular for $1b. Tabular was founded in 2021, had less than 50 employees and raised $37m. Jackpot. Accordingly to the press Snowflake and Confluent (Kafka) were also trying to buy Tabular.
But what is doing Tabular? Tabular is building a catalog for Apache Iceberg and Tabular employs a few part of Iceberg open-source contributors. By getting Tabular Databricks gets all the intellectual knowledge about Iceberg and how to build a catalog around it. - Open-sourcing Unity Catalog — Finally, on stage, Databricks' CEO hit the button to open-source Unity Catalog, directly responding to Snowflake’s open-sourcing of Polaris. Unity Catalog, previously a closed product, is now a key part of Databricks' strategy to become a the data platform. This move, combined with Tabular acquisition, will help Databricks achieve top-notch support for Iceberg.
If you've made it this far, you probably understand the story. Databricks is focusing on simplification (serverless, auto BI2, improved PySpark) while evolving into a data warehouse. With the open-sourcing of Unity Catalog and the adoption of Iceberg, Databricks is equipping users with the toolbox to build their own data warehouses.
Apache Iceberg and the catalogs
We finally get down to Iceberg. What's Iceberg? Why catalogs are so important? How do they differ to data catalog we are used to?
So Iceberg has been started at Netflix by Ryan Blue and Dan Weeks around 2017. Both co-founded later Tabular (which got acquired by Databricks). Iceberg has been designed to fix the flaws of Hive around table management, especially about ACID transactions. The project became a top-level Apache project in Nov 2018.
Currently Apache Iceberg competes with Delta Lake and Apache Hudi and became the leading format in the community when looking at all metrics. Newcomers are also arriving late to the party like nimble or DuckDB table format which could be a thing in the future.
What is Iceberg?
The community decided these last year and Parquet became the go-to file format when it comes to storing data. Parquet has many advantages like being columnar, the compression, can pushdown predicates, own the schema at file level and more. But there are a few issues with Parquet. Parquet is a storage format, except for a few metadata and the schema Parquet has lack of information about the table.
A table format creates an abstraction layer between you and the storage format, allowing you to interact with files in storage as if they were tables. This enables easier data management and query operations, making it possible to perform SQL-like operations and transactions directly on data files.
Iceberg is composed of 2 layers but has sublayers, like a onion:
- the data layer — contains the raw data in Parquet, Iceberg manages the way the Parquet files are partitioned, etc.
- the metadata layer
- manifest file — A manifest is an immutable Avro file that lists data files or delete files, along with each file’s partition data tuple, metrics, and tracking information.
- manifest list (or snapshot) — A new manifest list is written for each attempt to commit a snapshot because the list of manifests always changes to produce a new snapshot. This is simply a collection of manifests describing a state or a partial state of the table.
- metadata file — Table metadata is stored as JSON. Each table metadata change creates a new table metadata file that is committed by an atomic operation.
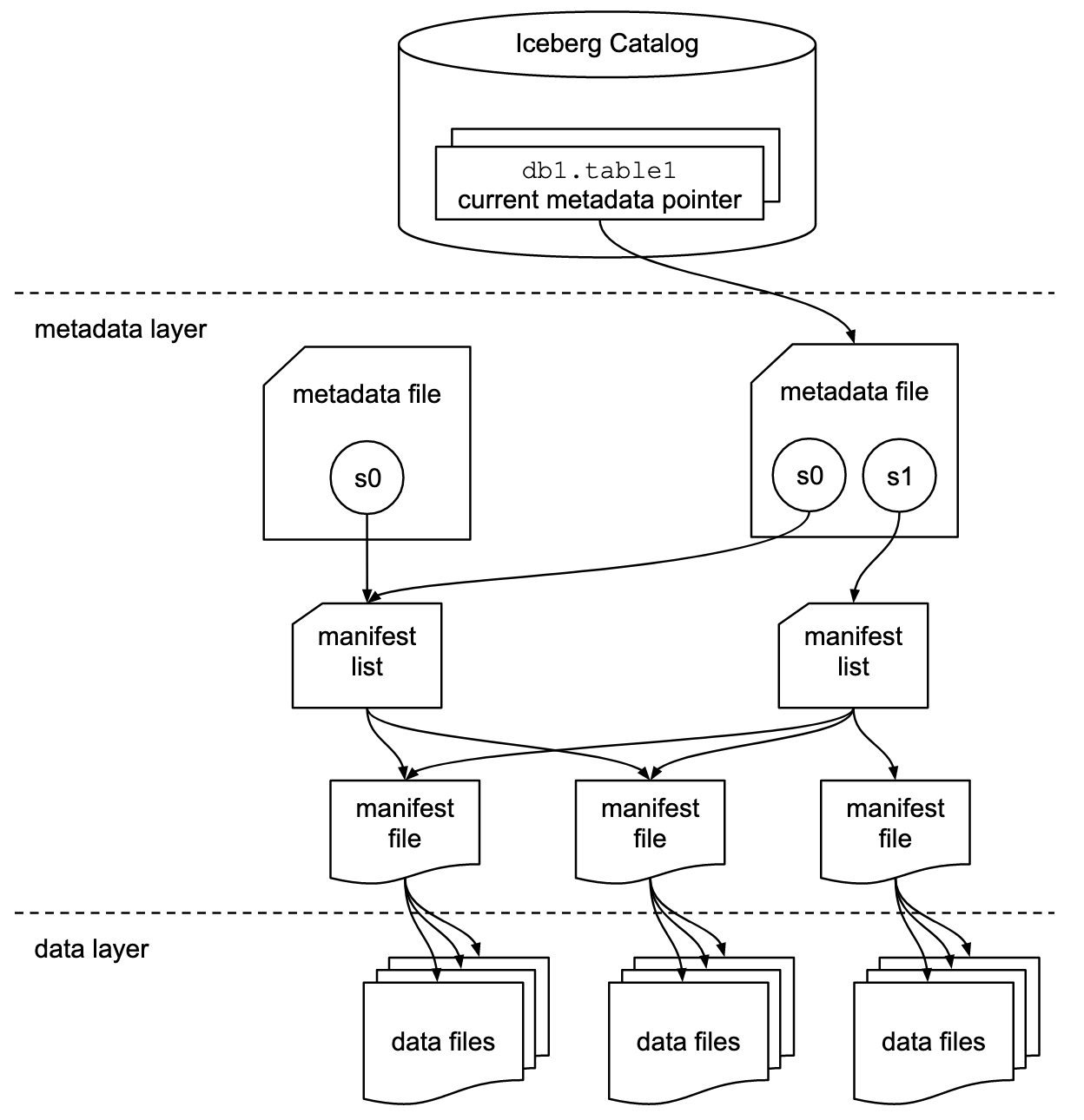
That's what it is, if you have to understand something, Iceberg creates table on-top of raw Parquet files.
So once you have Iceberg you're capable to create multiple tables, but you need a place to store all the metadata about your tables. Because Iceberg each table atomically but obviously you need more than one table. That's why you need a catalog. This catalog is like the Hive Metastore. I've read somewhere that we should call it a super metastore rather than a catalog which is already used to describe another product in the data community.
Still that's why we need a place to keep a track all our Iceberg tables. That's what is Unity Catalog, AWS Glue Data Catalog, Polaris, Iceberg Rest Catalog and Tabular (RIP). Actually all of these catalog are implementing the Iceberg REST Open API specification.
Conclusion
Databricks and Snowflake embracing Iceberg by open-sourcing a compatible catalog and opening their engines to Iceberg show how far ahead is Iceberg. I don't think Databricks or Snowflake really won the competition.
On Snowflake's side, they mitigated the impact by open-sourcing Polaris and embracing the Iceberg format. However, most Snowflake end-users won't be concerned with these changes ; they simply want to write SQL queries on their data. These format details are more relevant to data engineers. Snowflake finds itself between Databricks' innovation and BigQuery's simplicity3 (ingest data, query). To grow, Snowflake needs to expand in both directions.
With this move Databricks will finally provide a data warehouse to their customers, it will be a data warehouse in kit, but a data warehouse. Because this is what it is, the Iceberg + catalog combo just create a data warehouse. It mimics what a database is already doing for ages, but more in the open with you pulling all the levers rather than something hidden in a black box written in database compiled language like C.
Wait, Iceberg is written in Java, and honestly, PyIceberg is lagging significantly behind the Java version... Here we go again.
1 — I don't like the classic term to qualify AWS, Google and Microsoft but actually that's what they are right now. Leaders and commodities.
2 — I just made this term, looks like it does not exist for data really but I like it a lot.
3 — Actually recently BigQuery added a lot of features to extend the compute and with more way to interact with data (notebooks, canvas, etc.)

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.