Data News — Week 24.20
Data News #24.20 — Big edition, 5000 members ❤️, launching Qrators to search in videos, Data Council, OpenAI and Google I/O stuff and data eng stuff.

Hello you. The sun is out, the days are getting longer and Data News is still here. Next week marks 3 years of this newsletter/blog (yay 🎉 ). It'll be a time for looking back, reflecting and celebrating, but next week. This week, we reached 5000 members.
Yes, 5000 of you read my content periodically. Just thank you ❤️.
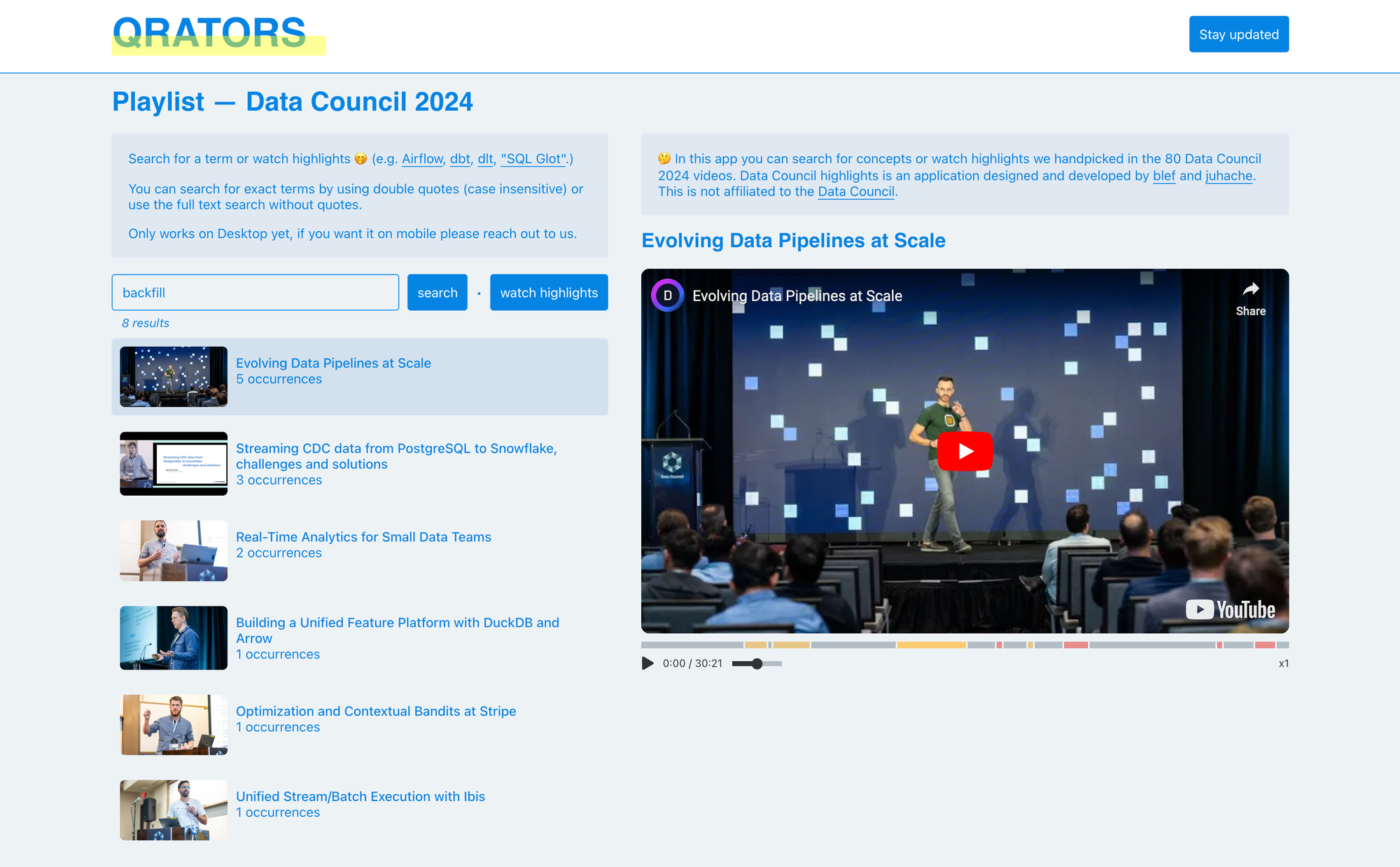
In the recent days I've been working on a new side project. What if you could search in video content and get the exact timestamp of what you're looking for?
Let me introduce an application of this on the Data Council 2024 80 videos.
Data Council 2024 ✨
Data Council Austin is according to me one of the best conference when it comes to think about the future of data. Every year the talk that are given at DC are always full of quality content. There is a main drawback of this which is: it 80 videos of ~30 minutes and not everyone have the time to watch everything or search among the videos.
So I developed an app which allows you to search for words in the Data Council video playlist and we've curated highlights with Julien in order for you to watch only what we've curated.
It's available on qrators (can be pronounced curators / creators). And it works for the moment only on desktop.
The search is working greatly, for instance you can full-text or exact-term search. For instance Airflow, dbt, backfill, "data mesh" or "SQL Glot". Quotes means an exact-term search.
I'll write another post later about the behind the scene and how this app has been built, but because I'm your humble servant, this app uses DuckDB WASM and requires no backend to work (except a bucket with the data).
Still, I want you to get as always a few takeaways of the conference so here are my favourite talks with a few highlights:
- Data culture as a product— Abhi already had one of my favourite talk from Data Council 2023 about Metrics tree. Following on from his work on metrics, this time he attempts to give advice on creating a good data culture in order to create a good decision culture in companies. After all, companies need to make decisions, and these decisions need to be informed by data. [highlights]
- Processing trillions of records at Okta with DuckDB instead of Snowflake — it was one of my most expected talk from the council because a few months ago Jake posted on LinkedIn his team successfully reduced Snowflake billing by hundred of thousands by shifting to DuckDB. In the talk he explained what was the issue with Snowflake and how a multi-engine data stack built on-top of S3 + Lambda drastically reduced dollars spent. [highlights]
I like a few of the others talks, but I'll do a dedicated post for this I think because the Data News is already super dense.
AI News 🤖
- OpenAI recents announcements — The company behind ChatGPT announced a few things hyping everyone recently. Especially their GPT-4o (it's 4-o the letter and not 40 the number) model, this model adds new capabilities to ChatGPT around photos, videos and audio. The model can talk or understand what's in a image/video and answer questions about it. They also released a MacOS app that you can call on Option+Space to ask ChatGPT. OpenAI also detailed a bit their model specs and what principles they implemented to put guardrails around answers.
- Why Microsoft invested in OpenAI in 2019 — Emails explaining why Satya Nadella (CEO) and Kevin Scott (CTO) pushed Microsoft to invest in OpenAI have been made public, and are worth a look. It mainly reads that Microsoft was "several years behind the competition in terms of ML scale" (compared to Google, in search / ML in applications) and that to get there, they needed someone with gigantic ambition, from silicon chips to high-level programming abstractions. And the OpenAI team was someone.
- OpenAI is offering $10m packages to top AI researchers. There is a paywall I can't say more.
- AI lobbyists are everywhere now — A bit more politic but with the stakes around AI (money, power, content moderation and generation, privacy, etc.) lobbying around it is through the roof.
- Google I/O keynote — Google I/O was the response from Google to OpenAI announcement around models. They showcased agents that can help you do more in your favourite Google Apps, then DeepMind showcases new capabilities around image and music processing / generation. But one of the most important announcement was only a few seconds about search that might change forever (paywall can be avoided with a page reader). Google introduced AI overview that will be presented first in search answer pushing traditional results far below.
- LLMs with Keras — Keras team demoed various workflows around LLMs (Gemma) with Keras.
- Opt-out to avoid Slack training LLM models on your private data — Slack (acquired by Salesforce) could train their LLM models on your data. Still their answered in the Twitter thread but it's legal stuff I don't understand.
- HuggingFace releases Idefics2 — An open multimodal model that accepts arbitrary sequences of image and text inputs and produces text outputs. Works with multiple images as well to create stories.
- Building DoorDash’s product knowledge graph with LLMs — A good graph is like good wine and DoorDash used LLMs capabilities in information extraction to improve their product catalog graph.

Fast News ⚡️
- Apache Arrow DataFusion becomes Apache DataFusion — DataFusion, a query engine built in Rust and uses Arrow for in-memory structures, has been promoted as a top-level Apache project. DataFusion is one of the most important alternative to DuckDB when it comes to engine (not mentioning polars here). On that topic this week I've met people from SDF who are betting on DataFusion as their core execution engine.
- facebook/nimble, a new columnar file format — A new columnar file format is out. They announce it as "a replacement for file formats such as Apache Parquet". Ok but why?
- Unexpected tips for data managers — A comprehensive and pragmatic list of tips to be a great data manager. This is pure gold.
- Data about data from 1,000 conversations with data teams — Mikkel output of his interviews with a lot of data teams and what topics are important.
- How to save 90% of BigQuery’s storage cost and how to reduce your Snowflake cost. On the same topic if you don't know about GROUP BY ROLLUP you should use it in Snowflake or BigQuery.
- Reverse engineering exercice — Awesome idea. In order to learn concepts the author decided to reverse engineered a NYT game and he documented the process and what he understood. I find this exercice super insightful and I'd love to do something similar.
- Initial thoughts on SQLMesh — A post describing what are the key concepts of SQLMesh (esp. around envs, plans and projects), this is a great introduction. Last week SQLMesh team also released stuff around testing, similar to dbt unit tests you can define input and outputs to test your models.
- dltHub REST API source toolkit — dlt released a toolkit to build extract and load pipelines on top of custom APIs. With the toolkit you can declare your endpoints resources and auth and then you'll be able to extract and load your data.
- Cube releases their AI API — Now you can query in natural language your semantic layer and get answers (it uses OpenAI). This is close to what I had demoed last year in a talk.
- MotherDuck pricing page — Great pricing page, competitors should get inspired from this. It's fun to play with it to see how many hundreds of thousands of dollars you would have spent.
- Uber, auto-categorizing an exabyte of data at field level through AI/ML — Reminds me SDF article about end-to-end classification of your data models but at Uber scale.
- great_tables — A great tool to create nice looking tables in Python on top of your dataframes.
Food for thought to end (because it's already too long)
- On Orchestrators: you are all right, but you are all wrong too
- Do you model in dbt or BI?
- How women lead data engineering at Slack
- How we migrated from dbt Cloud
- Lyft, build a strong data science team
See you next week for the anniversary 🎂

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.