Data News — Week 24.04
Data News #24.04 — Let's talk AI podcast interview, data & AI products conference, Disney VR floor, dbt awesome community projects.

Hey, new week new email. This is already end of January but I took time to travel and see people I did not see for a long time so I'm super happy how this new year is starting.
Next week, I'll be wrapping up my DataOps lecture by incorporating how to deploy machine learning models. This is a fun part where students learn how to serve a simple classifier in production. Building a custom HTTP API, Docker image and CI/CD processes making it accessible on internet. For the modern part this year, I'm going to integrate an LLM "classifier" part, it might attract their curiosity. We'll see.
Yesterday an interview I did for the podcast Let's talk AI has been published. Available everywhere. We talke about data engineering, freelancing and career stuff.

Data & AI products
Yesterday I went to 5h conference organised in Paris about Data & AI products—in French, the idea of the conference was to mix people coming from data and product ecosystem which is, let's be honest, the key enabler for AI in production. The recording will be online in a few days / weeks and I'll share them once online.
Here a few takeaways in a messy way:
- Data products and organisational impacts
- Data engineers are still the limiting human resource.
- Data mesh by the book will not work, if you want to scale you can't just add more people in a central team.
- Data mesh means decentralisation but more importantly ownership and responsibilities to team (esp. data producers)—if every team has to be responsible you need to have a easy-to-use platform and you have to explicitly give them responsibilities.
- UX for data products — This is a presentation I really enjoyed by Claire Lebarz, VP data at Malt. Without the voice you will miss a lot of things, still it contains great practicals tips.
- Before jumping to AI projects you need first to start with words and to define metrics reflecting [your] values. You don't want your AI to give bad product experience. So define—as a metric—what you don't want to have.
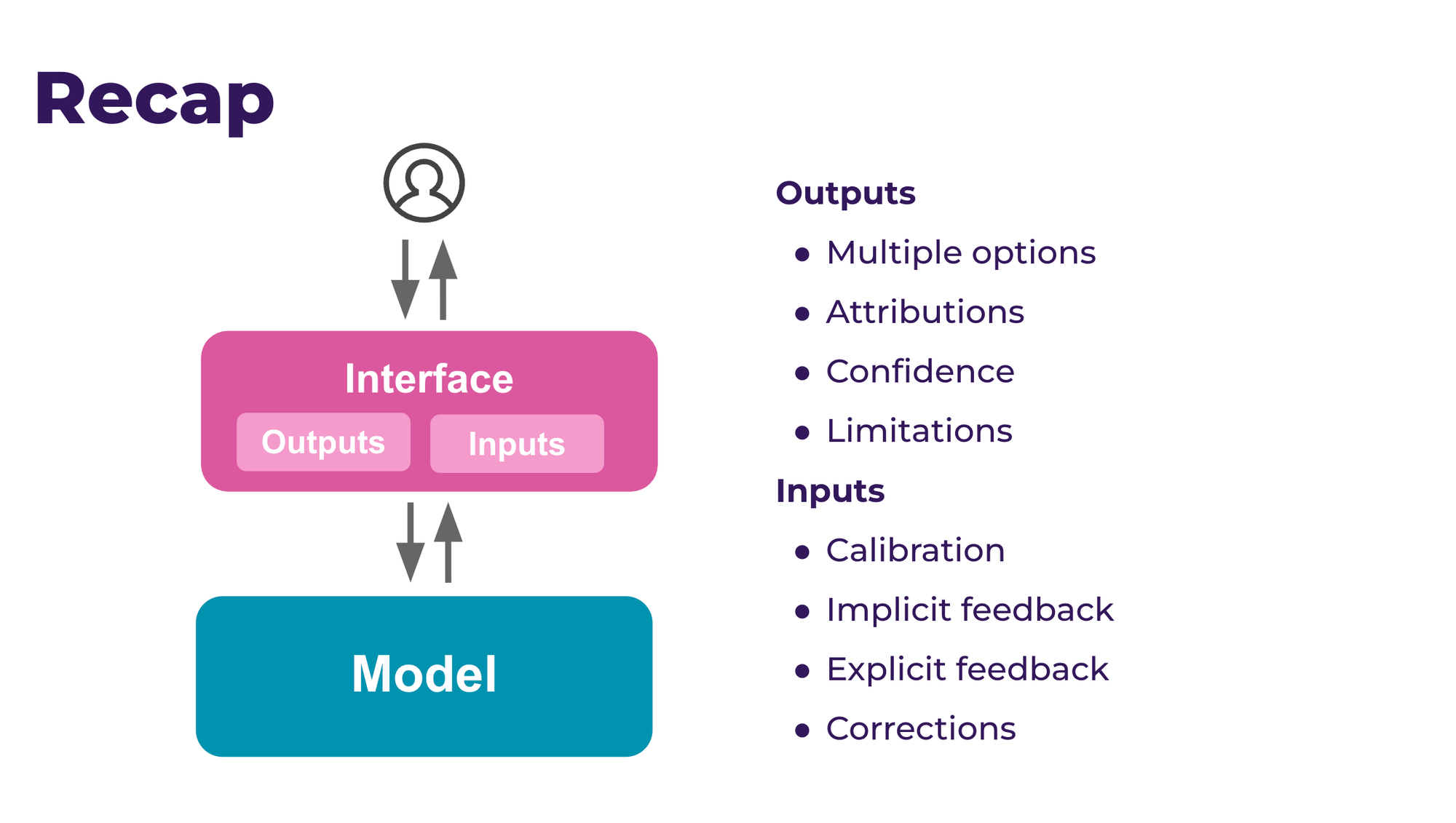
- Then Claire schematised human interaction with models (slide 8) via an interface with inputs and outputs. Inputs and outputs can be instrumented with multiple techniques that will empower people in their interaction with AI algorithm.
- Inputs — This is what you ask from the users to feed your algorithm. It can be done with calibration, implicit or explicit feedback and corrections.
- Outputs — Product design choices where you give power over the algorithm. It can be done with multiple options (like trips alternative on Google Maps), attributions (why something has been recommended), confidence interval (weather) or limitations.
- As data people you need to build relationships with designers to converge on common terms about human-AI interactions
- And other bits I got from the others talks
- OKR means metrics alignement across the company which lead to team autonomy—AI teams should be autonomous in finding solutions to move indicators
- It critical to have dashboards measuring success when AB testing models
- "Product is about people crafting together to best solutions and experiences to solve a customer problem" — Anne-Claire Baschet.
AI News 🤖
- This Chinese startup is winning the open source AI race — Thanks to Mistral AI open-source became the new standard among the community. There is a Chinese company called 01.ai who wants to build the first killer app of the Gen AI. (see also open-sourcing the future of AI, which is a HuggingFace praising post at some point).
- Hugging Face and Google partner for open AI — Do not mistake it's open AI and not OpenAI 😬. This partnership will benefit Google Cloud customers with unique hardware to train models and HuggingFace users will have some benefits but I did not understand the corporate sentences from the press release.
- OpenAI new embedding models and API updates — new Turbo models for 4.5 and 3.5 and 2 new embeddings models.
- Unleashing the power of LangChain — From POC to production, it showcases the LangChain expression language that helps developers chaining prompts in a nicer way.
Fast News ⚡️
- Disney Holotile VR floor — Disney developed a "dynamic" floor for VR use-cases. With it you can walk without really moving. This is a bit disturbing but it can unlock the metaverse future.
- ClickHouse and the one billion row challenge — ClickHouse proposed a SQL solution with ClickHouse local to the a challenge consisting in aggregating 1B rows in a text file. Initially this challenge has to be answered in Java. The leader submitted a solution running in less than 2s—have fun—while ClickHouse took 19s.
- SQLGlot switch to Rust — I really like SQLGlot, this is a SQL parser that gives you back the AST to do stuff. They ported the parser from Python to Rust and got 30-40% performance improvement.
- 2024 data engineering trends — We are still in January so it's still valid, Anna captured a few things that will make data teams busy this year. Firstly the reducing in resources leading teams to do more with less (or at least doing the same with less).
- Snowflake batch data loading — A good explanation of the Snowflake kCOPY INTO command and what you need to setup around it to make it work.
- Effective pandas 2 is out — I did not read the book. As pandas is, still, everywhere, it can be a good ressource if you need to learn the 2.0 version.
- Introducing girls to code, one flower at a time — An awesome initiative to introduce girls to code and data visualisation through creative coding projects, there is a Notion guidebook to do data visualisations with p5.js.
- The open-source enterprise data platform in a single portal — Bern local community open-sourced an data platform blueprints to launch an all-in-one data platform with dbt, Airflow and Superset on top of Postgres and K.
- Github/dbt-assertions — A dbt package to write dbt tests at row-level and to save exceptions alongside your failing rows (cf. example).
- PR comment template for dbt data projects — Great stuff. This is a proposal of Github pull request template when modifying dbt models. It includes description, lineage diff, illustration of model changes or impacts and more.
See you next week ❤️.

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.