Data News — Week 23.27
Data News #23.27 — My new French podcast, New vision for dbt Core semantic layer, langchain explained, carbon footprint of pizza.

Hey you, this is the Saturday Data News edition 🥲. Time flies. I'm working for the Series of articles in advance for August about "creating data platforms" and I'm looking for ideas about the data I could use for this. Having some kind of simulated real-time data would be the best. But it requires to write a simulation. Which is enough complicated. What would you use?
Small French aside 🇫🇷
(A small part in French, jump to next section)
Cette semaine j'ai lancé mon podcast en français nommé À l'heure des données. Dans ce podcast, qui sera mensuel, je vais discuter avec des experts francophones qui font l'écosystème. On discutera du présent mais aussi du futur.
Dans le premier épisode j'ai discuté avec Benoit Pimpaud qui a été data scientist à l'Olympique de Marseille et qui s'est reconverti plus tard chez Deezer en data engineer. Aujourd'hui il s'occupe du produit chez Kestra, un orchestrateur open-source développé en France.
🎧 Pour nous écouter : Apple — Spotify — Deezer — Amazon
Sue un tout autre sujet, Stéphane Bortzmeyer a participé au colloque du CNRS sur Penser et Créer avec les IA génératives et il a écrit un rapport sur ces 2 jours.
PS : est-ce qu'une version française de mon contenu t'intéresse ?
The new dbt Semantic Layer
Following the acquisition of Transform by dbt Labs a few months ago, dbt Core integrates MetricsFlow. MetricsFlow was the semantic layer of the acquired company. This week, Nick Handel, co-founder of ex-Transform, wrote about how dbt Core specs will adapt.
As a reminder a semantic layer is a definition on top of your models meant to be reusable. The idea, is then, to use the semantics to generate SQL queries. You can read my article on the semantic layer.
In the new vision it will be possible to define multiple things:
- entities —It defines the nodes of your business models. In a dbt model, you can define primary and foreign entities. A foreign entity defines an edge between models, hence a join in the final query.
- measures — A value aggregation.
- dimensions — A categorical or a time field than can be used either in a group by either in a filter.
- metrics — A pre-defined object that combines entities, measures and dimensions.
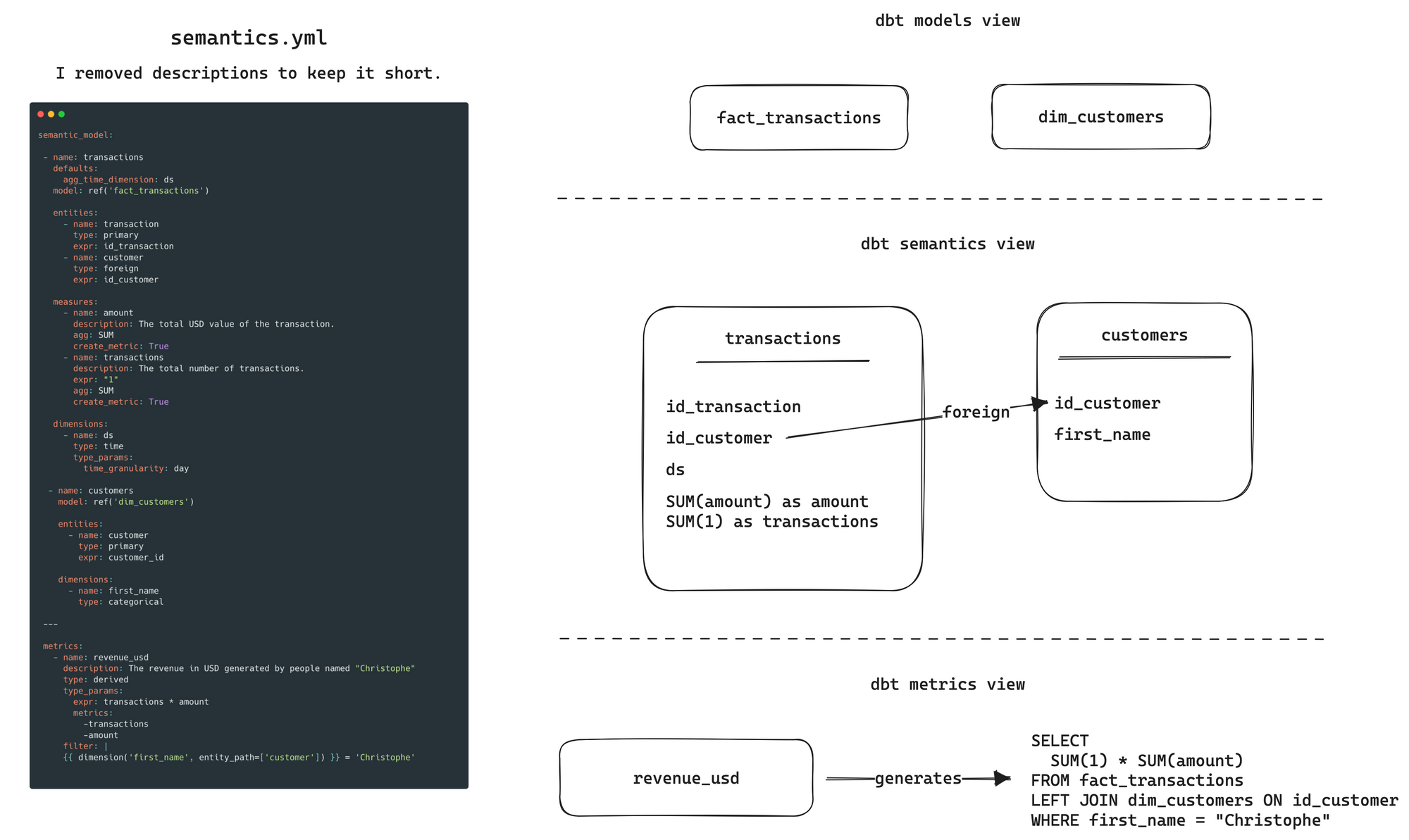
Just ahead I gave you an precise example of how the new nomenclature will behave for a simple case with a fact_transaction model. This is important to notice that the semantic layer is something that sits on top of you current dbt models definitions.
To complete the picture this is important to notice that the revenue_usd metrics can be queried at the moment either with a CLI, either via the API dbt Labs will release through their dbt Cloud offering.
As an extension I've seen 2 things this week that I feel makes sense here:
- VulcanSQL — A data API framework for DuckDB, Snowflake, BigQuery, PostgreSQL. Actually Vulcan let's you define in a blink parametrise SQL that you can expose through an API. It comes then with a catalog, a documentation and a way to connect downstream consumers tools (e.g. CSV exports, Excel, Sheets, etc.)
- A Rill Data dashboard about DuckDB commits — DuckDB commits is just an example. What I want to show here is Rill Data UI, while being relatively simple offers a standardise way to explore a dataset. On the left you get the metrics, on the right the dimensions, everything can be clickable and allows you to drill down. Under the hood it's "BI-as-code", YAML defining this dashboard can be found on Github.
These two examples are not really semantic layers in the strict sense, but revolve around the concept.
Gen AI 🤖
- Deploying Falcon-7B into production — If you want to launch your own open-source model on Kubernetes, this is a tutorial to do it.
- Langchain: explained and getting started — Langchain is a toolkit that lets you chain—what a surprise—components. Actually it's some kind of pipelines, every component as inputs and outputs and Langchain do the glue. Components includes stuff like prompts, LLMs, agents or memory.
- Langchain integrates Cube (the semantic layer) — Wrapping-up with previous category, Langchain can use Cube as a data loader.
- The rise of Vertical AI — Verticality in business always existed because it brings contextualisation. This articles described what will arrive on the market on top of Foundations and horizontal models that tries to be generic.
- Introducing NSQL: Open-source SQL Copilot Foundation models — This is a Foundation models that generates SQL, claiming to outperform others.
- Introducing Superalignment — Some stuff OpenAI wrote about the future (I did not read).
- CodeGen2.5: Small, but mighty — Salesforce released a new version of the CodeGen model. I hope they did not trained it on their internal code 🫠

Fast News ⚡️
- Career advice for aspiring progressive data professionals — Brittany has been working in progressive data for years and she's giving advices for people who wants to follow her path.
- Declarative data pipelines with Hoptimator — After trying to bring self-service for data pipelines at LinkedIn, they decided to go for declarative data pipelines supporting only a specific data movements. With YAML. We were visionary when we designed and developed this at Kapten 5 years ago.
- Airflow: scalable and cost-effective architecture — Hussein, an Airflow committer and PMC member, proposes an ideal architecture for big Airflow projects.
- Scaling data teams: 5 learnings — BlaBlaCar data team is well known in France now and recently embraced a data mesh organisation. Manu, the VP shares 5 learnings you should as a manager be aware of.
- Measuring the carbon footprint of pizzas 🍕 — Shit I've eaten a pizza yesterday. Max includes in the study 4 axes: agriculture, transformation, packaging, and transport. With this Margharita obviously is the less emitting one. 4x less than a Calzone with meat.
- Parquet file format explained — and how it compares with Avro & ORC.
- Iceberg won the table format war — Don't be click baited by the title, the article has been written by a dev rel at the company who mainly maintains Iceberg.
- Reducing data platform cost by $2m — How Razorpay optimised (mainly) their S3 storage (deletion, relocation) to save a lot of money.
- Every major announcement at Snowflake Summit — Another view than the one I shared last week by someone who actually was at the Summit.
- An intro video to open lineage, which is a important topic to give visibility over your data platform.
- Makefile tricks for Python projects — One of the best data magical trick. We repurposed old good Makefile to create simpler CLI on top of our daily tool. This is an article giving tips to make your best Makefiles.
- You can now GROUP BY ALL in Snowflake.
Data Economy 💰
- DigitalOcean acquires Paperspace. Paperspace is an all-in-one SaaS product to develop, train and deploy AI applications. With a custom Notebook UI based on Jupyter you can develop your models while checking at ressources, when the models is reading you can deploy it within containers.
- Redpanda raises $100m in Series C. Redpanda is a great product for developers. The best way to describe it is: this is a Kafka alternative. Built for modern times it removes most of the Kafka complexity by implementing all Kafka APIs.
See you next week ❤️

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.