
Tomorrow we'll enter in the last quarter of the year. This is crazy on how the time is flying. At the end of the year my freelancing activity will become my most significant professional experience. But at the same time I feel I've just started yesterday.
I'm so happy to see how to newsletter is turning these days. I really like to get feedbacks from you, so do not hesitate to reach me if you have something to say, it helps me a lot. In my plans I want to write more original content—that will be only for members (free and paid). But I struggle finding the time to do it. I need to rethink my time management and prioritisation. I'm super bad at it. How do you do it?
Data Fundraising 💰
As opposed to the last 2 weeks, fundraising are back this week. Money is coming back. But before, bad news. Docusign is laying off 9% of its staff.
- Unravel Data raised $50m Series D. They tick a lot of buzzwords in their tag line: DataOps Observability for the Modern data stack. It feels they do a lot of stuff to help data teams understand better their platform: monitor cloud costs, recommend performance tuning to apps and pipeline, help discover issues faster. In the end they do observability like others. As a side note, they still mention Oozie in their demos. Modern data stack they said.
- Coalesce raised $26m Series A. Coalesce is a boring drag and drop web UI to create data transformations for your Snowflake warehouse. Maybe they need money to pay the trademark lawsuit with dbt Labs regarding Coalesce term. They are fighting in court in the US and the UK (cf. Twitter) 🙄.
- Wasabi raised $250m Series D to fuel their the cloud storage alternative. Claiming 80% price cuts compared to AWS while being faster, it looks like a solid contender.
Are tables data products?
Data mesh initiative brings at his root the domain ownership to data teams. With simple words the major change is obviously organisational. It puts technical teams closer to their business. In this case you may have to look at the Conway law to define your teams topologies.
In order to get your teams ready for the big change you'll need to identify data products every team will deliver. Data products are entities on which you apply product principles. Data products, among other things, have to be interoperable, discoverable, shareable, bounded and owned.
And it applies very well to tables. Tables are highly interoperable, discoverable and shareable—ok it's depends on your storage/engine, but still it's more than decent. Also with some processes you can easily make the tables bounded and owned. So yes, we can say that tables can be considered as a sufficient data product. BUT, not every table in the warehouse should be considered like so. LinkedIn decided to name these data products the Super Tables.
At LinkedIn Super Tables are unit of work like the jobs or the ads_event table. For instance their jobs table consolidate more the 57 sources into 158 columns. Which obvioulsy means a lot, 57 sources into one table is probably more than the average data team use in a whole warehouse. Every ST should enforce SLA to reach 99%+ availability. It then creates datasets everyone in the company can trust and use in downstream data flows.
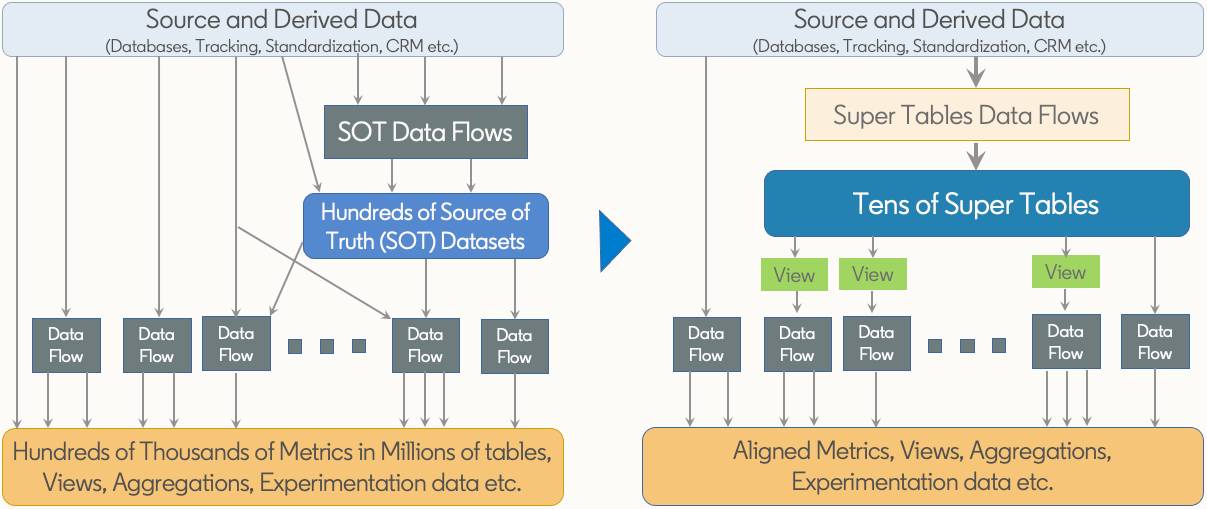
Creating a Super Table is not an easy task. You'll need to clearly identify why people need the data to create this common asset that delivers value to the stakeholders. With domain data teams it's easier to do it because team are closer to their sources and dedicated per business, so, they should know better what's needed.
But still, once you have all the requirements you'll need to apply data modeling super skills.
As a data modeler you can help leadership bring in millions of dollars in revenue by adjusting a few lines of code.
As a final note on this, everyone is speaking about Kimball but no one read him—I confess myself—Justin wrote a post about the 4-steps dimensional design every data modeler should follow to create a well architecture tables.
ML Friday 🤖
- Forecasting something that never happened — This is a good problem to have in machine learning and something I've seen multiple time. Luca describe how you can guess the uplift that will be generated by a promotion when you've never done it.
- 5 common data quality gotchas in Machine Learning — Doordash developed a DataQualityReport Python package that will help you identify missing values, invalid values and sampling errors while finding the distribution anomalies.

Fast News ⚡️
- Google released TensorStore a new way to store and manipulate arrays. I don't get what's the hidden power of this kind of innovation but I feel this is something when applied to PB brain images.
- How to use time travel on BigQuery tables — This is enabled by default and you can restore your table state at any point in time in the last 7 days.
- Use Snowflake data masking — Every warehouse should have a privacy layer. In Snowflake you can do it with masking policy. Masking policies are functions that will mask the data if queried without privileges. Philosophically it can be applied to every database engine—for instance Postgres.
- Evolution of streaming pipelines in Lyft’s marketplace — Lyft engineering team has been a leader of thoughts when it came to feature engineering. In this post they detail the different phase they went through years after years.
- Data quality automation at Twitter — Small article that details how Twitter developed their Data Quality Platform (DQP) on top of Great Expectations. In a nutshell they define rules in YAML files that are compile into Airflow DAGs that runs periodically to check if everything runs fine. In the end they show reports in Looker.
- The baffling maze of Kubernetes — Kubernetes is the far west. In the article Corey mentions that there isn't any consensus in the community as of now on how to develop iteratively on a Kube cluster. More than 25 products claiming to do it. On my side atm I'm deploying a bare-metal kube cluster and to be honest everyday I'm facing new issues, it reminds me good old Hadoop days.
- SaaS metrics reporting — What are the metrics you should follow when doing analytical work for a SaaS product.
- Comparing stateful stream processing and streaming databases.