I deleted data from production
I deleted data from production data platform. Read my stories and my takeaways, years after my mistakes.

The last few weeks have been busy with some huge downtimes. Facebook and OVH to name a few went totally down because of a wrong router configuration. Earlier in 2017 Gitlab got an outage because they accidentally removed data from the primary database and the backup was not working.
These incidents seem far from us — we are not at Facebook scale, we are not a hosting company like OVH or Gitlab — but still we are human, which means that we are not protected from totally destroying our beloved platforms in a blink.
In this post I would like to share my own personal experience regarding data loss and describe mistakes I did in the past. This is an educative and a therapeutic post in order to show that this is something normal and also to say it loud. If you understand French you can also watch the related YouTube video.
That time when I deleted the /usr folder
First story takes place in 2014, I was setuping an Hadoop cluster for a company. A small size cluster with less than ten nodes. I was far from being an expert because it was my first setup. I was trying to do my best and it was working. We were using Ambari and the cluster was working with one Namenode and some Datanodes.
And the issue appears. That day I got a The partition / is too full error in the Namenode. Big deal, the cluster was down. Small throwback, at that time I just graduated and I have experience in Linux administration but only to deal with personal websites and blogs I had as a teen. So I'm doing what everyone is probably doing: some Stack Overflow driven debugging and fixing.
I don't totally remember why but I was a bit stuck in the server and nothing was freeing space. I started to move big folders from the full partition to the data partition. The operation I was running was:
- copy the folder to the new data partition
- remove the old folder
- create a symlink between the new folder and the old path
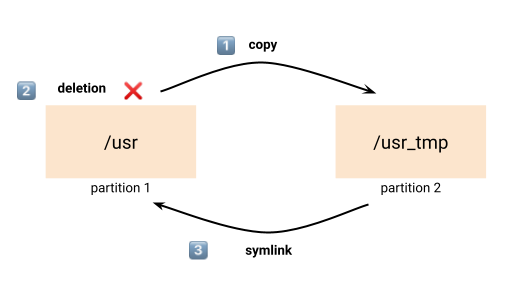
This solution is actually working for data folder, not for binaries, a not really for /usr.
Once I remove the /usr folder I got into big trouble. Yes, removing /usr means removing all Linux binaries. So, yeah, you are out. But actually with some creativity you can get back binaries, but the masterpiece is the sudo command. Sudo command needs to be owned by uid:0. The plan was not working. I was stuck outside of the Namenode and the cluster was still down.
That's when I asked for help. Also the reason I did not ask for help earlier was because the IT team needed ticket to work on topic and I wanted to fix the issue faster. What a champion.
In the end it wasn't a big issue — because the cluster was not yet in production. I lost a lot of time re-installing the cluster after the IT team fixed the issue and we change all partitions sizes. But if I had asked for help earlier it could have been fixed faster.
That time when I deleted /data folder
Like all horror stories everything is running fine until the disruptive element comes in. I was in another company and we often had morning pipeline issues so over the weekends I was frequently checking the Slack alerts channel. One morning I wake up happy and then I have a look at Slack. Nothing ran. The whole system was down, all pipelines were broken.
After a small deep-dive I see that it mentions that the /data folder is missing in HDFS. What a weird issue. How the f*ck this folder could not be present? Actually, that was true the folder was missing, then I send a message to the team asking if someone did something. In parallel I continued to dig and found that I was responsible of the deletion.
Argh 🙃.
If we can take a break. It's Sunday morning and I just discovered that I've lost 3To of data and that all data pipelines have stop working because on Friday I ran for no reason hdfs dfs -rm /data. What a nice day in perspective.
In the end we were able to get back around 60 to 80% of the data because a part of the data was still in data sources or in the BI tool cache layer. It took me around 3 days to get the system up again, but everything went fine in the end.
That time when a colleague did terraform destroy on the production project
Another company again and another story. But this time it wasn't my mistake but a colleague one and I was his manager.

One day, just before noon break, someone is asking on Slack: "Is Metabase down?". Usually we answer: "Are you on the VPN?" because it often the solution, but it was different this time. After a small check I also get a 502 bad gateway page from nginx.
We were in a open-space, it was pre-covid time, — do you still remember? — and I just look over my shoulder and see the screen of my colleague behind me. The screen is fully red. When I get closer I see a nice and welcoming terraform destroy at the top of the terminal. It should have run in staging but it was in production.
Even if you don't know this command you can understand by the word destroy what it could do. So, it was at noon and someone from the team destroyed the whole GCP data architecture we had, so we lost our Kubernetes cluster with apps (Airflow, Metabase, etc.), our GCE instances and our SQL instances. By chance our buckets and BigQuery weren't managed in terraform. So it limited the impacts.
I learnt a lot from this experience, I took us between 3 to 4 hours to put everything back up but as I wasn't the person who did the mistake I felt it differently. I had to be comforting with my colleague to help him fix the issue as fast as possible to get the numbers back up for everyone and to avoid us spending a night at work.
Takeaways
On each blunder I had different position and experience. First I was totally junior, then I had a more senior role and on the last one I was the manager. From my stories here some takeaways you can apply to you or your team to avoid this to produce:
- Create a good wheel environment, ask for help and do not hide stuff from colleagues
- Don't break under the pressure — easy to say and hard to do
- Never blame the responsible, I prefer to think that if the mistake happened it's because the team or the company let the issue happens — be also careful when you joke about it afterwards
- Measure the risk when you give all the permissions to one developer, one data engineer or one SRE — it means similar stories could happen
- Technically: do backups and test backups (cf. Gitlab), have audits on bash or admin commands, automatize everything (IaC - Terraform should be run from CI/CD for instance)
- Avoid copy pasting from internet if you don't understand the side effects
If I can also add as a last note, all the mistakes I did were on a data infrastructure and not on a client-facing product that could bring another level of stress in the troubleshooting.
If you already felt the same way I want you to know that you are not alone in this boat. It's ok to do mistakes. Learn from it.
If you feel overwhelmed with data I write a weekly curation do not hesitate to Subscribe. Obviously no spam and forever free.

blef.fr Newsletter
Join the newsletter to receive the latest updates in your inbox.